On June 12, 2026, OpenRouter launched Fusion, a productized API that does something deceptively simple: it runs multiple LLMs on the same prompt, has a judge model analyze their outputs, and synthesizes a single answer that is consistently better than any individual model could produce alone. The launch tweet made a claim that sounds like marketing until you look at the data: "Fusion achieves Fable-level intelligence at half the price." The DRACO benchmark results back it up, and the mechanism behind them changes how to think about the performance ceiling of LLM applications.
What Fusion actually does
The architecture is a three-stage pipeline that runs entirely server-side on OpenRouter's infrastructure:
Stage 1: Fan-out. The user's prompt is dispatched in parallel to a panel of N models. Each model runs independently with agentic tool access: web search and web fetch are enabled by default. Every panel member researches the question its own way, follows its own chain of reasoning, and selects its own sources. The Quality preset ships with Claude Opus Latest, OpenAI GPT Latest, and Google Gemini Pro Latest. The Budget preset uses cheaper models like Gemini Flash, Kimi, and DeepSeek.
Stage 2: Judge. A judge model reads every panel response and produces a structured breakdown. It does not pick the "best" answer. It extracts consensus points (where models agree), contradictions (where they diverge), partial coverage (what each model got right that others missed), unique insights, and blind spots. This structured analysis is the raw material for the final output.
Stage 3: Synthesis. The synthesizer model receives the structured analysis and writes the final answer, grounded in the consensus, resolving the contradictions, filling the coverage gaps, and avoiding the blind spots the judge identified. The caller gets back a single response in the same format as any regular model call.
The API integration is deliberately minimal. You replace your model slug:
{
"model": "openrouter/fusion",
"messages": [
{ "role": "user", "content": "What are the strongest arguments for and against carbon taxes?" }
]
}
Or you add Fusion as a tool that any model can self-escalate to:
{
"model": "anthropic/claude-sonnet-4",
"tools": [{ "type": "openrouter:fusion" }],
"messages": [...]
}
The tool-based pattern is the more interesting of the two. A cheap, fast model handles routine queries directly but calls Fusion when it encounters a question that warrants multi-model reasoning. It is the LLM equivalent of a junior associate who knows when to escalate to a panel of partners, and it keeps costs down for the 80% of queries that do not need the heavy machinery.
You can customize the panel by passing your own participant models and synthesizer:
{
"model": "openrouter/fusion",
"messages": [{ "role": "user", "content": "..." }],
"plugins": [{
"id": "fusion",
"model": "google/gemini-3-flash-preview",
"analysis_models": [
"google/gemini-3-flash-preview",
"moonshotai/kimi-k2.6",
"deepseek/deepseek-v4-pro"
]
}]
}
The benchmark: DRACO explained
OpenRouter chose DRACO because standard LLM benchmarks do not test what Fusion is built for. MMLU tests factual recall. GSM8K tests math reasoning. HumanEval tests code generation. None of them test the core capability Fusion targets: researching a complex question by synthesizing multiple sources into a comprehensive, well-cited analysis.
DRACO, published by Perplexity AI in February 2026, fills that gap. It contains 100 deep research tasks spanning 10 domains: academic research, finance, law, medicine, technology, UX design, general knowledge, needle-in-a-haystack retrieval, personalized assistance, and product comparison. The tasks draw on information sources from 40 countries and originate from anonymized, real-world Perplexity Deep Research requests that were then filtered and augmented.
Each task comes with a rubric of roughly 39.3 weighted criteria, on average, across four axes:
| Axis | Avg criteria per task | Weight range | What it tests |
|---|---|---|---|
| Factual Accuracy | 20.5 | -500 to +20 | Verifiable claims the response must get right |
| Breadth and Depth | 8.6 | -100 to +10 | Synthesis quality, trade-off analysis, actionable guidance |
| Presentation Quality | 5.6 | -50 to +20 | Terminology, formatting, readability, objective tone |
| Citation Quality | 4.8 | -150 to +10 | Primary source citations with working references |
The negative weights are what make DRACO hard to game. Of the 3,934 total criteria across all tasks, 415 are negative: penalties for errors. The most severe penalty, -500, is reserved for harmful medical recommendations. A hallucinated citation costs -150. A model that confidently states wrong information gets punished, not rewarded for verbosity.
The rubrics themselves were built by 26 domain experts (medical professionals, attorneys, financial analysts, software engineers, designers) through a four-stage process: initial construction, iterative peer review, a saturation test that sent back any rubric where Perplexity Deep Research scored above 90% (about 45% of tasks were returned), and a final QA pass. The result is a benchmark where a high score genuinely means the answer was thorough, accurate, and well-sourced.
The results
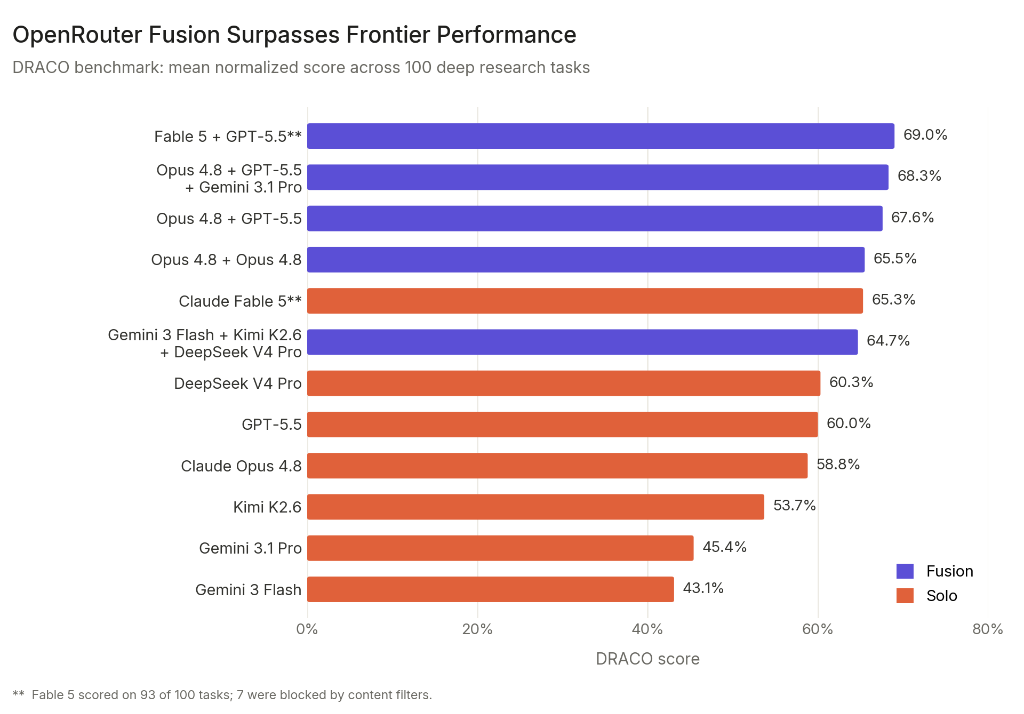
OpenRouter evaluated 11 configurations on DRACO: 5 fusion panels and 6 solo models. Here is the full table:
| Type | Configuration | DRACO Score |
|---|---|---|
| Fusion | Fable 5 + GPT-5.5, synthesized by Opus 4.8 | 69.0% |
| Fusion | Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro, synth. by Opus 4.8 | 68.3% |
| Fusion | Opus 4.8 + GPT-5.5, synth. by Opus 4.8 | 67.6% |
| Fusion | Opus 4.8 + Opus 4.8, synth. by Opus 4.8 | 65.5% |
| Solo | Claude Fable 5 (93 of 100 tasks) | 65.3% |
| Fusion | Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro, synth. by Opus 4.8 | 64.7% |
| Solo | DeepSeek V4 Pro | 60.3% |
| Solo | GPT-5.5 | 60.0% |
| Solo | Claude Opus 4.8 | 58.8% |
| Solo | Kimi K2.6 | 53.7% |
| Solo | Gemini 3.1 Pro | 45.4% |
| Solo | Gemini 3 Flash | 43.1% |
Three findings stand out.
Finding 1: Frontier panels exceed the frontier. The best fusion of frontier models (Fable 5 + GPT-5.5 at 69.0%) beat the best single model on the market (Fable 5 at 65.3%) by 3.7 points. No individual model matches this score. The performance ceiling is no longer defined by the strongest model you can access but by how well you combine them.
Finding 2: Budget panels beat frontier models. A panel of three budget models (Gemini 3 Flash, Kimi K2.6, DeepSeek V4 Pro at 64.7%) outscored GPT-5.5 (60.0%) and Opus 4.8 (58.8%). It landed within 1 point of Fable 5 (65.3%) at roughly half the cost.
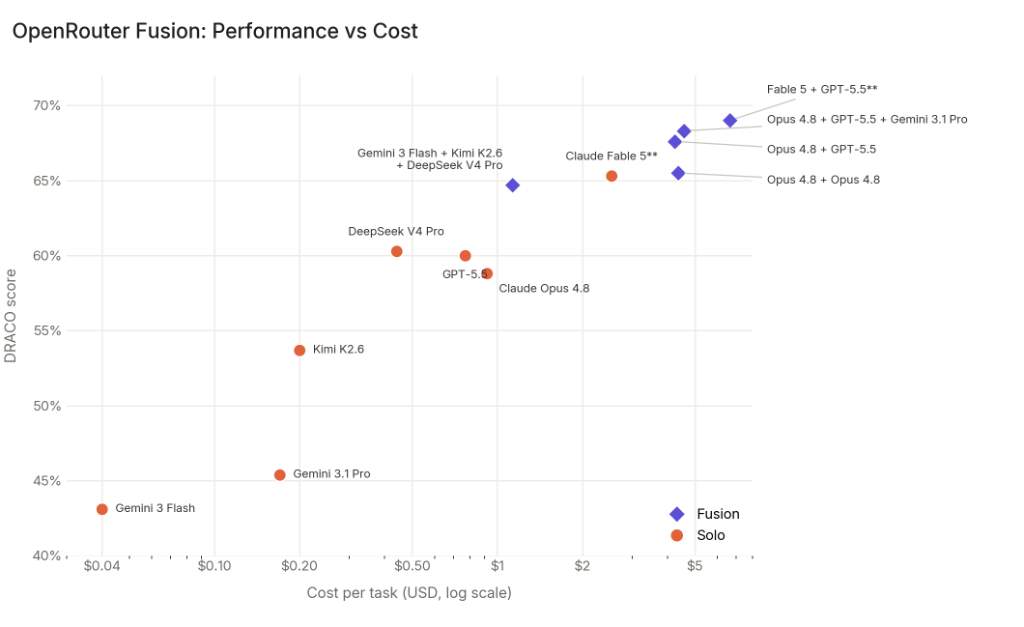
Finding 3: Synthesis, not diversity, drives most of the gain. This is the most revealing experiment in the entire study. OpenRouter ran Opus 4.8 fused with itself: same model, same architecture, no diversity at all, just Opus 4.8 running the prompt twice and a third Opus 4.8 call synthesizing the results. The score was 65.5%, a 6.7-point jump over solo Opus 4.8 at 58.8%.
Running the same model twice produces different reasoning paths, different tool calls, and different source selections. The judge and synthesizer exploit those differences. The implication is that roughly three quarters of Fusion's lift comes from the synthesis step itself, and one quarter from combining genuinely different model architectures. The bottleneck in compound AI is not which panel members you pick, it is how good your judge and synthesizer are.
The contamination discovery
One detail in the blog post deserves more attention than it has received. When OpenRouter gave the panel models web search, the models started finding the DRACO grading rubric online. This was not intentional cheating. The models were searching for relevant information on the research topics and stumbled onto pages hosting the benchmark rubrics.
OpenRouter solved it with a one-line config change: they added the benchmark domains to the excluded list on their server-side web search tool, which applies universally across all models. They then re-ran every experiment. All published results come from the clean setup.
The broader implication is uncomfortable for the entire benchmark industry. If web-enabled models can find grading rubrics through normal search, then any publicly hosted benchmark is potentially compromised for tool-enabled systems. Static, public benchmarks like MMLU and DRACO were designed for models that take a prompt and return text. They were not designed for models that can browse the web, find the answer key, and reference it without anyone noticing. Future benchmarks will need closed-domain evaluation environments, continuously refreshed task sets, or built-in contamination detection.
Where this fits in the trajectory
Fusion is not a new idea. It is the commercial productization of a research thread that runs through decades of machine learning.
Ensemble methods (bagging, boosting, random forests) established the core principle in the 1990s: combine weak learners and you get a strong learner. Mixture of Experts architectures, used inside GPT-4 and Mixtral, route inputs to specialized sub-networks within a single model. In 2023, Together AI published "Mixture-of-Agents," the first academic proposal to apply ensembling to multiple LLMs at inference time. In 2024, the "Compound AI Systems" framework from Berkeley formalized the shift from monolithic models to pipelines of LLM calls, tools, and orchestrators.
What changed to make Fusion possible now is threefold. First, model diversity reached critical mass: by mid-2026 there are five or more frontier-tier models from different labs with genuinely different architectures and training data. Second, API standardization matured: OpenRouter's unified API across 60+ providers means any model can be called with the same interface, which is the prerequisite for fanning out to a heterogeneous panel. Third, judge models became reliable enough: the DRACO paper reports 10 to 25 point shifts in absolute scores between different judge models, but relative rankings remain stable, which means the judge is good enough to extract consensus and contradictions even if its absolute calibration varies.
What this means for developers and model labs
For developers, the practical change is that the question "Claude or GPT?" becomes obsolete for hard tasks. You use both, fused, behind a single API call. For cost-sensitive workloads, the budget panel means you deliver frontier-adjacent quality without frontier pricing. The tool-invocation pattern lets any model self-escalate, creating a tiered intelligence system without manual routing logic.
For model labs, Fusion introduces a dynamic that is uncomfortable for their pricing power. If a panel of budget models can match the frontier, the premium that frontier models command erodes. Labs invest billions in training the strongest single model, but Fusion demonstrates that orchestration can substitute for raw model quality. This could push labs toward capabilities that are harder to replicate through ensembling: specialized reasoning, multimodal understanding, or agentic features that do not benefit from simple output fusion.
For OpenRouter specifically, Fusion transforms the company from a routing layer (commodity infrastructure that any competitor could replicate) into an intelligence multiplier. The quality of the synthesis step is proprietary. The infrastructure to run it at scale, with parallel model dispatch, server-side tool execution, and provider failover, is a multi-year engineering effort. Fusion makes the routing layer not just convenient but a measurable performance multiplier.
Limitations to keep in mind
The results are strong but come with caveats worth stating explicitly.
OpenRouter ran the benchmarks themselves. No independent third party has replicated the results. The judge model they used (Gemini 3.1 Pro Preview) differs from the DRACO paper's choice (Gemini 3 Pro), so their absolute scores are not directly comparable to the numbers in the paper. The paper itself warns that absolute scores shift 10 to 25 points depending on judge model, though relative system rankings are stable.
Claude Fable 5 only completed 93 of the 100 tasks because its content filters blocked 7. Its 65.3% is on a different task subset than every other configuration. OpenRouter acknowledges this makes direct comparisons "slightly uneven."
All results come from a single benchmark. Fusion's advantages on deep research tasks, where multiple sources need to be synthesized into a cited report, may not generalize to coding, creative writing, math, or simple Q&A. DRACO itself is text-only, English-only, and uses a static task set.
Fusion is in beta. Latency is higher than a single model call because the pipeline runs N models in parallel plus a judge plus a synthesizer. The cost advantage is per-quality-unit, not per-request. For high-throughput applications where latency matters, the trade-off may not be worth it.
The bottom line
OpenRouter Fusion is the first credible commercial productization of compound AI at the API level. The concept is not new, but the delivery is: one model slug, zero infrastructure, no orchestration code to write or debug. The benchmark results show that ensembles of existing models can exceed the frontier, and that the budget panel narrows the gap to the strongest single model at half the cost.
The most important finding is not the headline score. It is the Opus-plus-Opus experiment. When the synthesis step alone, with zero model diversity, produces a 6.7-point gain, the message is clear: the performance bottleneck in AI applications is shifting from model quality to orchestration intelligence. A better synthesizer with the same panel will outperform a worse synthesizer with a better panel. The model you call matters less than how you combine the calls.
For the broader AI ecosystem, Fusion is a signal that the next axis of competition is not just bigger models but smarter composition. The labs that win will be the ones that build the best orchestration layer, not just the best weights. OpenRouter just made that layer available with a single API call, and the Fable 5 story suddenly has a new competitor that does not need to train a better model to beat one.