Am 12. Juni 2026 hat OpenRouter Fusion vorgestellt, eine produktisierte API, die etwas täuschend Einfaches tut: Sie führt mehrere LLMs mit demselben Prompt aus, lässt ein Richter-Modell deren Ausgaben analysieren und synthetisiert eine einzige Antwort, die konsistent besser ist als alles, was ein einzelnes Modell allein produzieren könnte. Der Launch-Tweet machte eine Behauptung, die nach Marketing klingt, bis man sich die Daten ansieht: "Fusion erreicht Fable-Level-Intelligenz zum halben Preis." Die DRACO-Benchmark-Ergebnisse untermauern das, und der Mechanismus dahinter verändert, wie man über die Leistungsobergrenze von LLM-Anwendungen denken sollte.
Was Fusion tatsächlich tut
Die Architektur ist eine dreistufige Pipeline, die vollständig serverseitig auf der Infrastruktur von OpenRouter läuft:
Stufe 1: Fan-out. Der Prompt des Nutzers wird parallel an ein Panel aus N Modellen gesendet. Jedes Modell läuft unabhängig mit agentischem Tool-Zugriff: Websuche und Web-Fetch sind standardmäßig aktiviert. Jedes Panel-Mitglied recherchiert die Frage auf seine eigene Weise, folgt seiner eigenen Argumentationskette und wählt seine eigenen Quellen. Die Quality-Voreinstellung wird mit Claude Opus Latest, OpenAI GPT Latest und Google Gemini Pro Latest ausgeliefert. Die Budget-Voreinstellung nutzt günstigere Modelle wie Gemini Flash, Kimi und DeepSeek.
Stufe 2: Richter. Ein Richter-Modell liest jede Panel-Antwort und erzeugt eine strukturierte Aufschlüsselung. Es wählt nicht die "beste" Antwort aus. Es extrahiert Konsens-Punkte (wo Modelle übereinstimmen), Widersprüche (wo sie divergieren), Teilabdeckung (was jedes Modell richtig hatte, das andere übersahen), einzigartige Erkenntnisse und blinde Flecken. Diese strukturierte Analyse ist das Rohmaterial für die endgültige Ausgabe.
Stufe 3: Synthese. Das Synthesizer-Modell erhält die strukturierte Analyse und schreibt die endgültige Antwort, verankert im Konsens, die Widersprüche auflösend, die Abdeckungslücken füllend und die blinden Flecken vermeidend, die der Richter identifiziert hat. Der Aufrufer erhält eine einzelne Antwort im gleichen Format wie bei jedem normalen Modellaufruf.
Die API-Integration ist bewusst minimal. Man ersetzt den Modell-Slug:
{
"model": "openrouter/fusion",
"messages": [
{ "role": "user", "content": "What are the strongest arguments for and against carbon taxes?" }
]
}
Oder man fügt Fusion als Tool hinzu, zu dem jedes Modell selbst eskalieren kann:
{
"model": "anthropic/claude-sonnet-4",
"tools": [{ "type": "openrouter:fusion" }],
"messages": [...]
}
Das toolbasierte Muster ist das interessantere der beiden. Ein günstiges, schnelles Modell bearbeitet Routine-Anfragen direkt, ruft aber Fusion, wenn es auf eine Frage stößt, die Multi-Modell-Argumentation rechtfertigt. Es ist das LLM-Äquivalent eines Junior-Assistenten, der weiß, wann er zu einem Partner-Panel eskalieren muss, und es hält die Kosten für die 80% der Anfragen niedrig, die die schwere Maschinerie nicht benötigen.
Das Panel kann angepasst werden, indem eigene Teilnehmer-Modelle und ein Synthesizer übergeben werden:
{
"model": "openrouter/fusion",
"messages": [{ "role": "user", "content": "..." }],
"plugins": [{
"id": "fusion",
"model": "google/gemini-3-flash-preview",
"analysis_models": [
"google/gemini-3-flash-preview",
"moonshotai/kimi-k2.6",
"deepseek/deepseek-v4-pro"
]
}]
}
Der Benchmark: DRACO erklärt
OpenRouter wählte DRACO, weil Standard-LLM-Benchmarks nicht testen, wofür Fusion gebaut wurde. MMLU testet faktisches Erinnern. GSM8K testet mathematisches Reasoning. HumanEval testet Codegenerierung. Keiner von ihnen testet die Kernfähigkeit, auf die Fusion abzielt: die Recherche zu einer komplexen Frage durch die Synthese mehrerer Quellen zu einer umfassenden, gut zitierten Analyse.
DRACO, veröffentlicht von Perplexity AI im Februar 2026, füllt diese Lücke. Es enthält 100 Aufgaben für tiefe Recherche aus 10 Domänen: akademische Forschung, Finanzen, Recht, Medizin, Technologie, UX-Design, Allgemeinwissen, Needle-in-a-Haystack-Retrieval, personalisierte Assistenz und Produktvergleich. Die Aufgaben greifen auf Informationsquellen aus 40 Ländern zurück und stammen aus anonymisierten, realen Perplexity-Deep-Research-Anfragen, die anschließend gefiltert und erweitert wurden.
Jede Aufgabe kommt mit einer Rubrik von durchschnittlich etwa 39,3 gewichteten Kriterien über vier Achsen:
| Achse | Ø Kriterien pro Aufgabe | Gewichtungsbereich | Was getestet wird |
|---|---|---|---|
| Faktische Genauigkeit | 20,5 | -500 bis +20 | Überprüfbare Aussagen, die die Antwort richtig haben muss |
| Breite und Tiefe | 8,6 | -100 bis +10 | Synthesequalität, Trade-off-Analyse, umsetzbare Empfehlungen |
| Präsentationsqualität | 5,6 | -50 bis +20 | Terminologie, Formatierung, Lesbarkeit, objektiver Ton |
| Zitierqualität | 4,8 | -150 bis +10 | Primärquellen-Zitationen mit funktionierenden Referenzen |
Die negativen Gewichtungen sind es, die DRACO schwer zu manipulieren machen. Von den insgesamt 3.934 Kriterien über alle Aufgaben sind 415 negativ: Strafen für Fehler. Die härteste Strafe, -500, ist schädlichen medizinischen Empfehlungen vorbehalten. Eine halluzinierte Zitation kostet -150. Ein Modell, das selbstbewusst falsche Informationen darstellt, wird bestraft, nicht für Weitschweifigkeit belohnt.
Die Rubriken selbst wurden von 26 Domänenexperten (medizinisches Fachpersonal, Anwälte, Finanzanalysten, Softwareingenieure, Designer) durch einen vierstufigen Prozess erstellt: anfängliche Konstruktion, iteratives Peer-Review, ein Sättigungstest, der jede Rubrik zurückschickte, bei der Perplexity Deep Research über 90% erzielte (etwa 45% der Aufgaben wurden zurückgegeben), und eine abschließende QA-Überprüfung. Das Ergebnis ist ein Benchmark, bei dem eine hohe Punktzahl tatsächlich bedeutet, dass die Antwort gründlich, korrekt und gut belegt war.
Die Ergebnisse
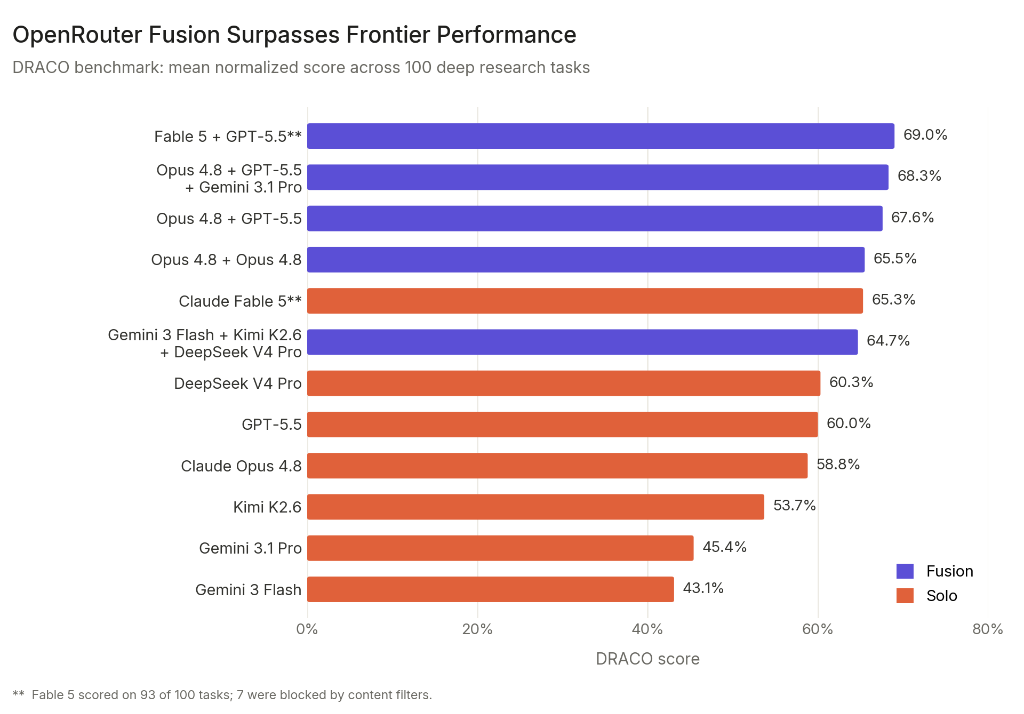
OpenRouter evaluierte 11 Konfigurationen auf DRACO: 5 Fusion-Panels und 6 Solo-Modelle. Hier ist die vollständige Tabelle:
| Typ | Konfiguration | DRACO-Punktzahl |
|---|---|---|
| Fusion | Fable 5 + GPT-5.5, synthetisiert von Opus 4.8 | 69,0% |
| Fusion | Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro, synth. von Opus 4.8 | 68,3% |
| Fusion | Opus 4.8 + GPT-5.5, synth. von Opus 4.8 | 67,6% |
| Fusion | Opus 4.8 + Opus 4.8, synth. von Opus 4.8 | 65,5% |
| Solo | Claude Fable 5 (93 von 100 Aufgaben) | 65,3% |
| Fusion | Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro, synth. von Opus 4.8 | 64,7% |
| Solo | DeepSeek V4 Pro | 60,3% |
| Solo | GPT-5.5 | 60,0% |
| Solo | Claude Opus 4.8 | 58,8% |
| Solo | Kimi K2.6 | 53,7% |
| Solo | Gemini 3.1 Pro | 45,4% |
| Solo | Gemini 3 Flash | 43,1% |
Drei Erkenntnisse stechen hervor.
Erkenntnis 1: Frontier-Panels übertreffen die Frontier. Die beste Fusion aus Frontier-Modellen (Fable 5 + GPT-5.5 bei 69,0%) schlug das beste Einzelmodell auf dem Markt (Fable 5 bei 65,3%) um 3,7 Punkte. Kein Einzelmodell erreicht diese Punktzahl. Die Leistungsobergrenze wird nicht mehr durch das stärkste Modell definiert, auf das man zugreifen kann, sondern dadurch, wie gut man sie kombiniert.
Erkenntnis 2: Budget-Panels schlagen Frontier-Modelle. Ein Panel aus drei Budget-Modellen (Gemini 3 Flash, Kimi K2.6, DeepSeek V4 Pro bei 64,7%) übertraf GPT-5.5 (60,0%) und Opus 4.8 (58,8%). Es landete innerhalb eines Punktes von Fable 5 (65,3%), bei ungefähr halben Kosten.
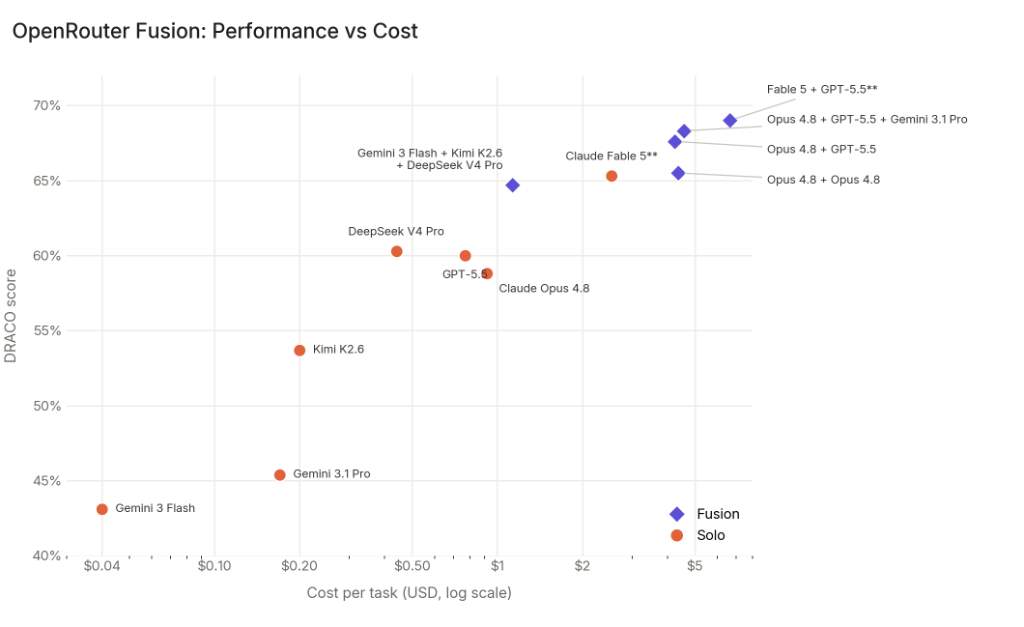
Erkenntnis 3: Synthese, nicht Vielfalt, treibt den Großteil des Gewinns. Dies ist das aufschlussreichste Experiment in der gesamten Studie. OpenRouter ließ Opus 4.8 mit sich selbst fusioniert laufen: dasselbe Modell, dieselbe Architektur, keinerlei Vielfalt, nur Opus 4.8, das den Prompt zweimal ausführte, und ein dritter Opus-4.8-Aufruf, der die Ergebnisse synthetisierte. Die Punktzahl betrug 65,5%, ein Sprung von 6,7 Punkten gegenüber Solo-Opus 4.8 bei 58,8%.
Wird dasselbe Modell zweimal ausgeführt, ergeben sich unterschiedliche Argumentationspfade, Tool-Aufrufe und Quellenauswahlen. Der Richter und der Synthesizer nutzen diese Unterschiede. Die Implikation ist, dass etwa drei Viertel des Fusion-Lifts aus dem Synthese-Schritt selbst stammen, und ein Viertel aus der Kombination wirklich unterschiedlicher Modellarchitekturen. Der Engpass in Compound AI ist nicht, welche Panel-Mitglieder man auswählt, sondern wie gut Richter und Synthesizer sind.
Die Kontaminations-Entdeckung
Ein Detail im Blogbeitrag verdient mehr Aufmerksamkeit, als es erhalten hat. Als OpenRouter den Panel-Modellen Websuche gab, begannen die Modelle, die DRACO-Bewertungsrubrik online zu finden. Dies war kein absichtliches Schummeln. Die Modelle suchten nach relevanten Informationen zu den Recherchethemen und stießen auf Seiten, die die Benchmark-Rubriken hosteten.
OpenRouter löste es mit einer einzeiligen Konfigurationsänderung: Sie fügten die Benchmark-Domänen zur Ausschlussliste des serverseitigen Websuche-Tools hinzu, die universell für alle Modelle gilt. Anschließend führten sie jedes Experiment erneut durch. Alle veröffentlichten Ergebnisse stammen aus dem sauberen Setup.
Die breitere Implikation ist unbequem für die gesamte Benchmark-Branche. Wenn webfähige Modelle Bewertungsrubriken durch normale Suche finden können, dann ist jeder öffentlich gehostete Benchmark potenziell für toolfähige Systeme kompromittiert. Statische, öffentliche Benchmarks wie MMLU und DRACO wurden für Modelle entwickelt, die einen Prompt annehmen und Text zurückgeben. Sie wurden nicht für Modelle entwickelt, die das Web durchsuchen, den Antwortschlüssel finden und darauf verweisen können, ohne dass es jemand bemerkt. Zukünftige Benchmarks werden geschlossene Evaluationsumgebungen, kontinuierlich aktualisierte Aufgabensätze oder eingebaute Kontaminationserkennung benötigen.
Wo dies in den Verlauf passt
Fusion ist keine neue Idee. Es ist die kommerzielle Produktrealisierung eines Forschungsstrangs, der sich durch Jahrzehnte des maschinellen Lernens zieht.
Ensemble-Methoden (Bagging, Boosting, Random Forests) etablierten das Kernprinzip in den 1990er Jahren: Kombiniere schwache Lerner und du erhältst einen starken Lerner. Mixture-of-Experts-Architekturen, die in GPT-4 und Mixtral verwendet werden, leiten Inputs an spezialisierte Sub-Netzwerke innerhalb eines einzelnen Modells weiter. 2023 veröffentlichte Together AI "Mixture-of-Agents", den ersten akademischen Vorschlag, Ensembling auf mehrere LLMs zur Inferenzzeit anzuwenden. 2024 formalisierte das "Compound AI Systems"-Framework aus Berkeley den Wandel von monolithischen Modellen zu Pipelines aus LLM-Aufrufen, Tools und Orchestratoren.
Was Fusion jetzt möglich macht, ist dreierlei. Erstens erreichte die Modellvielfalt eine kritische Masse: Mitte 2026 gibt es fünf oder mehr Frontier-Modelle verschiedener Labore mit wirklich unterschiedlichen Architekturen und Trainingsdaten. Zweitens reifte die API-Standardisierung: OpenRouters einheitliche API über 60+ Anbieter bedeutet, dass jedes Modell mit derselben Schnittstelle aufgerufen werden kann, was die Voraussetzung dafür ist, auf ein heterogenes Panel zu fächern. Drittens wurden Richter-Modelle zuverlässig genug: Das DRACO-Paper berichtet über Verschiebungen der absoluten Punktzahlen um 10 bis 25 Punkte zwischen verschiedenen Richter-Modellen, aber die relativen Rankings bleiben stabil, was bedeutet, dass der Richter gut genug ist, um Konsens und Widersprüche zu extrahieren, selbst wenn seine absolute Kalibrierung variiert.
Was das für Entwickler und Modelllabore bedeutet
Für Entwickler ist die praktische Änderung, dass die Frage "Claude oder GPT?" für schwierige Aufgaben obsolet wird. Man nutzt beide, fusioniert, hinter einem einzigen API-Aufruf. Für kostenkritische Workloads bedeutet das Budget-Panel, dass man Frontier-nahe Qualität ohne Frontier-Preise liefert. Das Tool-Aufruf-Muster lässt jedes Modell selbst eskalieren und schafft ein abgestuftes Intelligenzsystem ohne manuelle Routing-Logik.
Für Modelllabore führt Fusion eine Dynamik ein, die für ihre Preismacht unbequem ist. Wenn ein Panel aus Budget-Modellen die Frontier erreichen kann, erodiert die Prämie, die Frontier-Modelle erzielen. Labore investieren Milliarden in das Training des stärksten Einzelmodells, aber Fusion zeigt, dass Orchestrierung rohe Modellqualität ersetzen kann. Dies könnte Labore in Richtung Fähigkeiten drängen, die schwerer durch Ensembling zu replizieren sind: spezialisiertes Reasoning, multimodales Verständnis oder agentische Features, die nicht von einfacher Output-Fusion profitieren.
Für OpenRouter im Besonderen verwandelt Fusion das Unternehmen von einer Routing-Schicht (Commodity-Infrastruktur, die jeder Konkurrent replizieren könnte) zu einem Intelligenz-Multiplikator. Die Qualität des Synthese-Schritts ist proprietär. Die Infrastruktur, um dies im großen Maßstab zu betreiben, mit parallelem Model-Dispatch, serverseitiger Tool-Ausführung und Provider-Failover, ist eine mehrjährige Engineering-Anstrengung. Fusion macht die Routing-Schicht nicht nur bequem, sondern zu einem messbaren Leistungs-Multiplikator.
Einschränkungen, die man im Auge behalten sollte
Die Ergebnisse sind stark, kommen aber mit Vorbehalten, die es explizit zu nennen gilt.
OpenRouter hat die Benchmarks selbst durchgeführt. Keine unabhängige Drittpartei hat die Ergebnisse repliziert. Das Richter-Modell, das sie verwendeten (Gemini 3.1 Pro Preview), unterscheidet sich von der Wahl des DRACO-Papers (Gemini 3 Pro), daher sind ihre absoluten Punktzahlen nicht direkt mit den Zahlen im Paper vergleichbar. Das Paper selbst warnt, dass sich absolute Punktzahlen um 10 bis 25 Punkte verschieben, je nach Richter-Modell, obwohl die relativen System-Rankings stabil sind.
Claude Fable 5 absolvierte nur 93 der 100 Aufgaben, da seine Content-Filter 7 blockierten. Seine 65,3% beziehen sich auf eine andere Aufgaben-Teilmenge als jede andere Konfiguration. OpenRouter räumt ein, dass dies direkte Vergleiche "leicht ungleichmäßig" macht.
Alle Ergebnisse stammen aus einem einzigen Benchmark. Fusions Vorteile bei Aufgaben für tiefe Recherche, bei denen mehrere Quellen zu einem zitierten Bericht synthetisiert werden müssen, generalisieren möglicherweise nicht auf Coding, kreatives Schreiben, Mathematik oder einfache Q&A. DRACO selbst ist text-only, englischsprachig und verwendet einen statischen Aufgabensatz.
Fusion befindet sich in der Beta-Phase. Die Latenz ist höher als bei einem einzelnen Modellaufruf, da die Pipeline N Modelle parallel plus einen Richter und einen Synthesizer ausführt. Der Kostenvorteil gilt pro Qualitätseinheit, nicht pro Anfrage. Für hochdurchsatzstarke Anwendungen, bei denen Latenz zählt, lohnt sich der Trade-off möglicherweise nicht.
Das Fazit
OpenRouter Fusion ist die erste glaubwürdige kommerzielle Produktrealisierung von Compound AI auf API-Ebene. Das Konzept ist nicht neu, aber die Bereitstellung: ein Modell-Slug, null Infrastruktur, kein Orchestrierungs-Code zum Schreiben oder Debuggen. Die Benchmark-Ergebnisse zeigen, dass Ensembles bestehender Modelle die Frontier übertreffen können, und dass das Budget-Panel die Lücke zum stärksten Einzelmodell bei halben Kosten verringert.
Die wichtigste Erkenntnis ist nicht die Schlagzeilen-Punktzahl. Es ist das Opus-plus-Opus-Experiment. Wenn der Synthese-Schritt allein, mit null Modellvielfalt, einen Gewinn von 6,7 Punkten erzeugt, ist die Botschaft eindeutig: Der Leistungsengpass in KI-Anwendungen verschiebt sich von der Modellqualität zur Orchestrierungsintelligenz. Ein besserer Synthesizer mit demselben Panel wird einen schlechteren Synthesizer mit einem besseren Panel übertreffen. Das Modell, das man aufruft, ist weniger wichtig als wie man die Aufrufe kombiniert.
Für das breitere KI-Ökosystem ist Fusion ein Signal, dass die nächste Wettbewerbsachse nicht nur größere Modelle sind, sondern intelligentere Komposition. Die Labore, die gewinnen, werden diejenigen sein, die die beste Orchestrierungsschicht bauen, nicht nur die besten Gewichte. OpenRouter hat diese Schicht gerade mit einem einzigen API-Aufruf verfügbar gemacht, und die Fable-5-Story hat plötzlich einen neuen Wettbewerber, der kein besseres Modell trainieren muss, um eins zu schlagen.