Le 12 juin 2026, OpenRouter a lancé Fusion, une API produit qui fait quelque chose de faussement simple : elle exécute plusieurs LLM sur le même prompt, fait analyser leurs sorties par un modèle juge, et synthétise une réponse unique qui est systématiquement meilleure que ce qu'un modèle individuel aurait pu produire seul. Le tweet de lancement avançait une affirmation qui ressemble à du marketing jusqu'à ce qu'on regarde les données : « Fusion atteint une intelligence de niveau Fable à moitié prix ». Les résultats du benchmark DRACO le confirment, et le mécanisme derrière ces résultats change la façon de penser le plafond de performance des applications LLM.
Ce que Fusion fait réellement
L'architecture est un pipeline en trois étapes qui s'exécute entièrement côté serveur sur l'infrastructure d'OpenRouter :
Étape 1 : Fan-out. Le prompt de l'utilisateur est dispatché en parallèle à un panel de N modèles. Chaque modèle tourne indépendamment avec un accès agentique aux outils : la recherche web et le web fetch sont activés par défaut. Chaque membre du panel recherche la question à sa manière, suit sa propre chaîne de raisonnement, et sélectionne ses propres sources. Le preset Quality est livré avec Claude Opus Latest, OpenAI GPT Latest, et Google Gemini Pro Latest. Le preset Budget utilise des modèles moins chers comme Gemini Flash, Kimi, et DeepSeek.
Étape 2 : Juge. Un modèle juge lit chaque réponse du panel et produit une décomposition structurée. Il ne choisit pas la « meilleure » réponse. Il extrait les points de consensus (où les modèles s'accordent), les contradictions (où ils divergent), la couverture partielle (ce que chaque modèle a bien eu et que les autres ont manqué), les insights uniques, et les angles morts. Cette analyse structurée est la matière première de la sortie finale.
Étape 3 : Synthèse. Le modèle synthétiseur reçoit l'analyse structurée et écrit la réponse finale, ancrée dans le consensus, en résolvant les contradictions, en comblant les lacunes de couverture, et en évitant les angles morts identifiés par le juge. L'appelant récupère une seule réponse dans le même format que n'importe quel appel de modèle classique.
L'intégration API est délibérément minimale. Vous remplacez votre slug de modèle :
{
"model": "openrouter/fusion",
"messages": [
{ "role": "user", "content": "What are the strongest arguments for and against carbon taxes?" }
]
}
Ou vous ajoutez Fusion comme outil que n'importe quel modèle peut auto-déclencher :
{
"model": "anthropic/claude-sonnet-4",
"tools": [{ "type": "openrouter:fusion" }],
"messages": [...]
}
Le pattern basé outil est le plus intéressant des deux. Un modèle bon marché et rapide gère directement les requêtes de routine, mais appelle Fusion quand il rencontre une question qui justifie un raisonnement multi-modèles. C'est l'équivalent LLM d'un jeune associé qui sait quand escalader vers un panel de partenaires, et cela maintient les coûts bas pour les 80 % de requêtes qui n'ont pas besoin de la machinerie lourde.
Vous pouvez personnaliser le panel en passant vos propres modèles participants et synthétiseur :
{
"model": "openrouter/fusion",
"messages": [{ "role": "user", "content": "..." }],
"plugins": [{
"id": "fusion",
"model": "google/gemini-3-flash-preview",
"analysis_models": [
"google/gemini-3-flash-preview",
"moonshotai/kimi-k2.6",
"deepseek/deepseek-v4-pro"
]
}]
}
Le benchmark : DRACO décrypté
OpenRouter a choisi DRACO parce que les benchmarks LLM standards ne testent pas ce pour quoi Fusion a été conçu. MMLU teste le rappel factuel. GSM8K teste le raisonnement mathématique. HumanEval teste la génération de code. Aucun d'eux ne teste la capacité centrale que Fusion cible : rechercher une question complexe en synthétisant plusieurs sources dans une analyse complète et bien citée.
DRACO, publié par Perplexity AI en février 2026, comble ce manque. Il contient 100 tâches de recherche approfondie réparties sur 10 domaines : recherche académique, finance, droit, médecine, technologie, design UX, connaissances générales, retrieval de type aiguille dans une botte de foin, assistance personnalisée, et comparaison de produits. Les tâches s'appuient sur des sources d'information provenant de 40 pays et sont issues de requêtes anonymisées du Perplexity Deep Research réel, ensuite filtrées et augmentées.
Chaque tâche est accompagnée d'une grille d'environ 39,3 critères pondérés, en moyenne, sur quatre axes :
| Axe | Moy. critères par tâche | Plage de poids | Ce qui est testé |
|---|---|---|---|
| Exactitude factuelle | 20,5 | -500 à +20 | Affirmations vérifiables que la réponse doit avoir justes |
| Largeur et profondeur | 8,6 | -100 à +10 | Qualité de synthèse, analyse de compromis, recommandations exploitables |
| Qualité de présentation | 5,6 | -50 à +20 | Terminologie, mise en forme, lisibilité, ton objectif |
| Qualité des citations | 4,8 | -150 à +10 | Citations de sources primaires avec références fonctionnelles |
Les poids négatifs sont ce qui rend DRACO difficile à manipuler. Sur les 3 934 critères totaux à travers toutes les tâches, 415 sont négatifs : des pénalités pour les erreurs. La pénalité la plus sévère, -500, est réservée aux recommandations médicales dangereuses. Une citation hallucinée coûte -150. Un modèle qui assène avec assurance des informations incorrectes est puni, pas récompensé pour sa verbosité.
Les grilles elles-mêmes ont été construites par 26 experts du domaine (professionnels de santé, avocats, analystes financiers, ingénieurs logiciels, designers) à travers un processus en quatre étapes : construction initiale, revue par les pairs itérative, un test de saturation qui renvoyait toute grille où Perplexity Deep Research obtenait plus de 90 % (environ 45 % des tâches ont été retournées), et une passe finale d'assurance qualité. Le résultat est un benchmark où un score élevé signifie véritablement que la réponse était approfondie, exacte et bien sourcée.
Les résultats
OpenRouter a évalué 11 configurations sur DRACO : 5 panels de fusion et 6 modèles en solo. Voici le tableau complet :
| Type | Configuration | Score DRACO |
|---|---|---|
| Fusion | Fable 5 + GPT-5.5, synthétisé par Opus 4.8 | 69.0% |
| Fusion | Opus 4.8 + GPT-5.5 + Gemini 3.1 Pro, synth. par Opus 4.8 | 68.3% |
| Fusion | Opus 4.8 + GPT-5.5, synth. par Opus 4.8 | 67.6% |
| Fusion | Opus 4.8 + Opus 4.8, synth. par Opus 4.8 | 65.5% |
| Solo | Claude Fable 5 (93 tâches sur 100) | 65.3% |
| Fusion | Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro, synth. par Opus 4.8 | 64.7% |
| Solo | DeepSeek V4 Pro | 60.3% |
| Solo | GPT-5.5 | 60.0% |
| Solo | Claude Opus 4.8 | 58.8% |
| Solo | Kimi K2.6 | 53.7% |
| Solo | Gemini 3.1 Pro | 45.4% |
| Solo | Gemini 3 Flash | 43.1% |
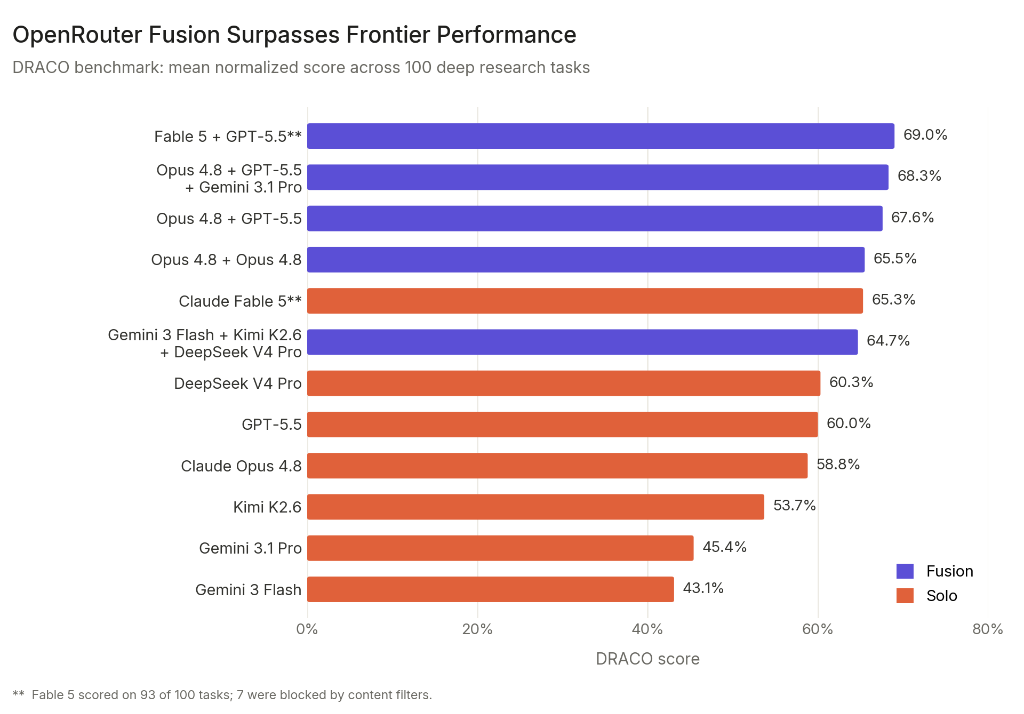
Trois constats se détachent.
Constat 1 : les panels frontière dépassent la frontière. La meilleure fusion de modèles frontière (Fable 5 + GPT-5.5 à 69,0 %) bat le meilleur modèle unique du marché (Fable 5 à 65,3 %) de 3,7 points. Aucun modèle individuel n'égale ce score. Le plafond de performance n'est plus défini par le modèle le plus puissant auquel vous pouvez accéder, mais par la qualité de leur combinaison.
Constat 2 : les panels économiques battent les modèles frontière. Un panel de trois modèles économiques (Gemini 3 Flash, Kimi K2.6, DeepSeek V4 Pro à 64,7 %) surpasse GPT-5.5 (60,0 %) et Opus 4.8 (58,8 %). Il se place à un point de Fable 5 (65,3 %) pour un coût d'environ la moitié.
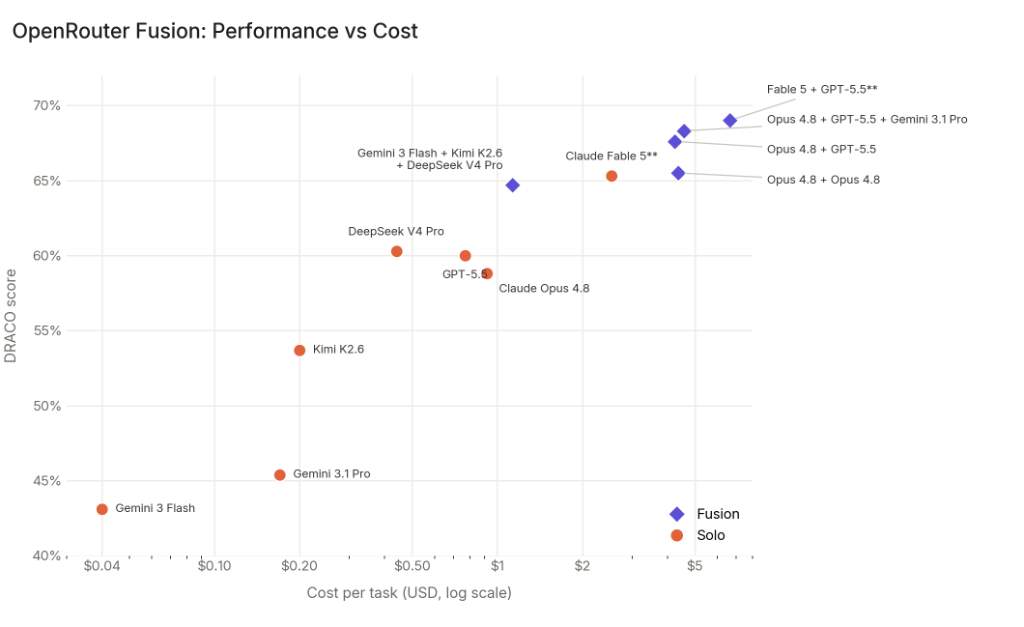
Constat 3 : c'est la synthèse, pas la diversité, qui tire l'essentiel du gain. C'est l'expérience la plus révélatrice de toute l'étude. OpenRouter a fait tourner Opus 4.8 fusionné avec lui-même : même modèle, même architecture, zéro diversité, juste Opus 4.8 qui exécute le prompt deux fois et un troisième appel Opus 4.8 qui synthétise les résultats. Le score a été de 65,5 %, un bond de 6,7 points par rapport à Opus 4.8 solo à 58,8 %.
Faire tourner le même modèle deux fois produit des chemins de raisonnement, des appels d'outils et des sélections de sources différents. Le juge et le synthétiseur exploitent ces différences. L'implication est qu'environ les trois quarts du gain de Fusion proviennent de l'étape de synthèse elle-même, et un quart de la combinaison d'architectures de modèles véritablement différentes. Le goulot d'étranglement du compound AI n'est pas le choix des membres du panel, c'est la qualité du juge et du synthétiseur.
La découverte de contamination
Un détail du billet de blog mérite plus d'attention qu'il n'en a reçu. Quand OpenRouter a donné aux modèles du panel l'accès à la recherche web, les modèles ont commencé à trouver la grille de notation de DRACO en ligne. Ce n'était pas de la triche intentionnelle. Les modèles cherchaient des informations pertinentes sur les sujets de recherche et sont tombés sur des pages hébergeant les grilles du benchmark.
OpenRouter l'a résolu par un changement de configuration d'une ligne : ils ont ajouté les domaines du benchmark à la liste d'exclusion de leur outil de recherche web côté serveur, qui s'applique universellement à tous les modèles. Ils ont ensuite réexécuté chaque expérience. Tous les résultats publiés proviennent de la configuration propre.
L'implication plus large est inconfortable pour l'ensemble de l'industrie des benchmarks. Si des modèles avec accès au web peuvent trouver les grilles de notation via une recherche normale, alors tout benchmark publiquement hébergé est potentiellement compromis pour les systèmes avec outils. Les benchmarks statiques et publics comme MMLU et DRACO ont été conçus pour des modèles qui prennent un prompt et renvoient du texte. Ils n'ont pas été conçus pour des modèles qui peuvent naviguer sur le web, trouver le corrigé, et le consulter sans que personne ne s'en aperçoive. Les benchmarks futurs auront besoin d'environnements d'évaluation en domaine fermé, de jeux de tâches rafraîchis en continu, ou d'une détection de contamination intégrée.
Où cela s'inscrit dans la trajectoire
Fusion n'est pas une idée nouvelle. C'est la commercialisation d'un fil de recherche qui traverse des décennies de machine learning.
Les méthodes d'ensemble (bagging, boosting, forêts aléatoires) ont établi le principe central dans les années 1990 : combinez des apprenants faibles et vous obtenez un apprenant fort. Les architectures Mixture of Experts, utilisées au cœur de GPT-4 et Mixtral, routent les entrées vers des sous-réseaux spécialisés au sein d'un même modèle. En 2023, Together AI a publié « Mixture-of-Agents », la première proposition académique d'appliquer l'ensembling à plusieurs LLM au moment de l'inférence. En 2024, le framework « Compound AI Systems » de Berkeley a formalisé le passage de modèles monolithiques à des pipelines d'appels LLM, d'outils et d'orchestrateurs.
Trois choses ont changé pour rendre Fusion possible maintenant. Premièrement, la diversité des modèles a atteint une masse critique : à la mi-2026, il existe cinq modèles de niveau frontière ou plus issus de laboratoires différents, avec des architectures et des données d'entraînement réellement distinctes. Deuxièmement, la standardisation des API a mûri : l'API unifiée d'OpenRouter sur plus de 60 fournisseurs signifie que n'importe quel modèle peut être appelé avec la même interface, ce qui est le prérequis pour répartir un prompt sur un panel hétérogène. Troisièmement, les modèles juges sont devenus suffisamment fiables : l'article DRACO rapporte des décalages de 10 à 25 points dans les scores absolus entre différents modèles juges, mais les classements relatifs restent stables, ce qui signifie que le juge est assez bon pour extraire consensus et contradictions même si sa calibration absolue varie.
Ce que cela signifie pour les développeurs et les laboratoires de modèles
Pour les développeurs, le changement pratique est que la question « Claude ou GPT ? » devient obsolète pour les tâches difficiles. Vous utilisez les deux, fusionnés, derrière un seul appel API. Pour les charges de travail sensibles au coût, le panel économique permet de livrer une qualité proche de la frontière sans le prix frontière. Le pattern d'invocation d'outils permet à n'importe quel modèle de s'auto-escalader, créant un système d'intelligence à plusieurs niveaux sans logique de routage manuelle.
Pour les laboratoires de modèles, Fusion introduit une dynamique inconfortable pour leur pouvoir de tarification. Si un panel de modèles économiques peut égaler la frontière, la prime que les modèles frontière commandent s'érode. Les laboratoires investissent des milliards dans l'entraînement du meilleur modèle unique, mais Fusion démontre que l'orchestration peut se substituer à la qualité brute du modèle. Cela pourrait pousser les laboratoires vers des capacités plus difficiles à répliquer via l'ensembling : raisonnement spécialisé, compréhension multimodale, ou fonctionnalités agentiques qui ne bénéficient pas d'une simple fusion de sorties.
Pour OpenRouter spécifiquement, Fusion transforme l'entreprise, passant d'une couche de routage (infrastructure de base que n'importe quel concurrent pourrait répliquer) à un multiplicateur d'intelligence. La qualité de l'étape de synthèse est propriétaire. L'infrastructure pour la faire tourner à l'échelle, avec dispatch parallèle des modèles, exécution d'outils côté serveur et basculement entre fournisseurs, représente un effort d'ingénierie de plusieurs années. Fusion rend la couche de routage non seulement pratique, mais un multiplicateur de performance mesurable.
Limites à garder à l'esprit
Les résultats sont solides, mais s'accompagnent de réserves qu'il vaut la peine d'énoncer explicitement.
OpenRouter a exécuté les benchmarks elle-même. Aucun tiers indépendant n'a reproduit les résultats. Le modèle juge utilisé (Gemini 3.1 Pro Preview) diffère de celui de l'article DRACO (Gemini 3 Pro), donc leurs scores absolus ne sont pas directement comparables aux chiffres de l'article. L'article lui-même prévient que les scores absolus varient de 10 à 25 points selon le modèle juge, bien que les classements relatifs des systèmes restent stables.
Claude Fable 5 n'a terminé que 93 tâches sur 100 parce que ses filtres de contenu en ont bloqué 7. Son 65,3 % porte sur un sous-ensemble de tâches différent de toutes les autres configurations. OpenRouter reconnaît que cela rend les comparaisons directes « légèrement inégales ».
Tous les résultats proviennent d'un benchmark unique. Les avantages de Fusion sur les tâches de recherche approfondie, où plusieurs sources doivent être synthétisées en un rapport cité, peuvent ne pas se généraliser au code, à l'écriture créative, aux maths ou au simple Q&R. DRACO lui-même est en texte seul, en anglais seul, et utilise un jeu de tâches statique.
Fusion est en bêta. La latence est plus élevée qu'un appel de modèle unique parce que le pipeline exécute N modèles en parallèle plus un juge plus un synthétiseur. L'avantage de coût est par unité de qualité, pas par requête. Pour les applications à haut débit où la latence compte, le compromis peut ne pas valoir le coup.
L'essentiel
OpenRouter Fusion est la première commercialisation crédible du compound AI au niveau de l'API. Le concept n'est pas nouveau, mais la livraison l'est : un slug de modèle, zéro infrastructure, pas de code d'orchestration à écrire ou à déboguer. Les résultats du benchmark montrent que des ensembles de modèles existants peuvent dépasser la frontière, et que le panel économique réduit l'écart avec le meilleur modèle unique pour moitié coût.
Le constat le plus important n'est pas le score phare. C'est l'expérience Opus-plus-Opus. Quand l'étape de synthèse seule, avec zéro diversité de modèles, produit un gain de 6,7 points, le message est clair : le goulot d'étranglement de performance dans les applications IA se déplace de la qualité du modèle vers l'intelligence d'orchestration. Un meilleur synthétiseur avec le même panel surpassera un moins bon synthétiseur avec un meilleur panel. Le modèle que vous appelez compte moins que la façon dont vous combinez les appels.
Pour l'écosystème IA au sens large, Fusion est un signal que le prochain axe de compétition n'est pas seulement des modèles plus gros, mais une composition plus intelligente. Les laboratoires qui gagneront seront ceux qui construiront la meilleure couche d'orchestration, pas seulement les meilleurs poids. OpenRouter vient de mettre cette couche à disposition en un seul appel API, et l'histoire de Fable 5 a soudain un nouveau concurrent qui n'a pas besoin d'entraîner un meilleur modèle pour en battre un.